Restez toujours informé: suivez-nous sur Google Actualités (icone ☆)
Le Laboratoire d'informatique du parallélisme (LIP - CNRS/ENS Lyon/Université de Lyon) fête ses 30 ans. Focus sur une des thématiques emblématiques du laboratoire: la tolérance aux pannes pour les plates-formes de calcul comprenant des milliers de processeurs qui subissent à l'heure actuelle de l'ordre d'une panne par jour sur les super-calculateurs les plus puissants !
©CNRS
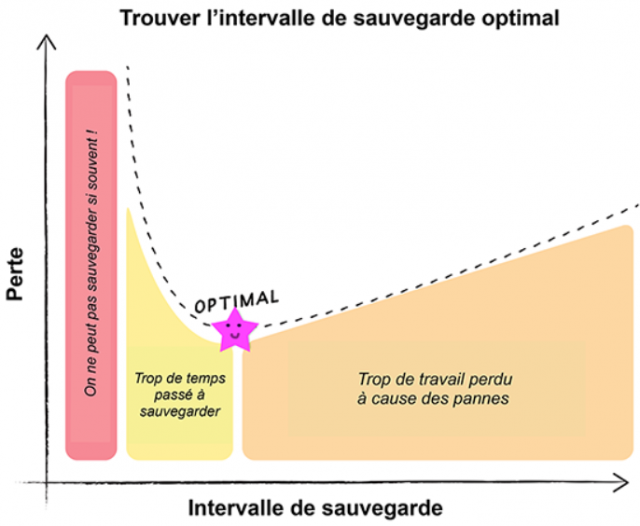
Pour illustrer cette problématique, commençons par un exemple, celui d'Alice. Alice travaille sur son vieil ordinateur portable, qui n'est pas très fiable. Naturellement, Alice décide d'effectuer régulièrement des sauvegardes de son travail sur un disque externe. Une sauvegarde prend trois minutes, alors Alice décide de sauvegarder toutes les trois heures. Le troisième jour, ce qui devait arriver arriva, le portable tombe en panne et Alice doit rebooter ; en plus elle perd l'équivalent d'1h30 de travail ! Elle décide alors de sauvegarder plus souvent, toutes les demi-heures. Seulement voilà, elle finit par réaliser que cette nouvelle stratégie lui laisse moins de temps pour travailler ! Alors, à quelle fréquence doit-elle sauvegarder son travail ?
La réponse à la question d'Alice dépend du taux de pannes: plus les pannes sont fréquentes, plus il faut sauvegarder souvent. Pour un autre travail, Alice travaille en parallèle avec Bob, et leur travail est perdu si l'un des deux ordinateurs tombe en panne. Les sauvegardes sont faites simultanément sur les deux ordinateurs afin qu'il soit possible de redémarrer ensemble après une panne. Dans ce contexte, il y aura des pannes deux fois plus souvent ! Pour modéliser le taux de panne, on mesure tout d'abord le temps moyen entre deux fautes (MTBF, Mean Time Between Failures). La probabilité d'occurrence d'une panne ne dépend pas des pannes passées. Pour une plate-forme avec p processeurs de MTBF identiques, on peut démontrer mathématiquement que le MTBF de la plate-forme correspond aux MTBF individuels / p, formalisant le fait qu'Alice et Bob ont des pannes deux fois plus souvent que lorsqu'Alice travaillait seule !
En étudiant les pertes liées au coût des sauvegardes, ainsi que les pertes suites aux pannes (travail perdu, temps pour redémarrer la machine et récupérer la dernière sauvegarde), on peut exprimer la perte totale en fonction de la fréquence des sauvegardes, et dire à Alice quand elle doit sauvegarder son travail !
Cet exemple illustre la problématique de la tolérance aux pannes avec le cas de fautes que l'on détecte immédiatement (erreurs fatales) [1]. Mais il y a en fait plusieurs classes d'erreurs fatales, et on peut envisager de faire des sauvegardes à plusieurs niveaux. Il faut alors décider quand et où sauvegarder [2].
Les erreurs dites silencieuses touchent également de plus en plus les applications à haute performance. Ces erreurs peuvent facilement passer inaperçues, il s'agit par exemple d'une corruption d'un bit en mémoire, et à terme l'application peut renvoyer une erreur ou un résultat erroné. Il est donc nécessaire de pouvoir détecter de telles erreurs avec un système de vérification, et il faut alors décider à quelle fréquence vérifier, en plus de sauvegarder [3]. Si plusieurs vérificateurs sont disponibles (de fiabilités et de coûts différents), on doit décider de l'intervalle de vérification pour chacun de ces vérificateurs [4].
Enfin, des techniques alternatives à la sauvegarde sont également étudiées, comme par exemple la réplication, qui consiste à dupliquer le travail afin de ne pas perdre de temps lors d'une panne. Cette technique nécessite des ressources supplémentaires, et doit donc être utilisée avec prudence. Il est possible de coupler les deux techniques, en particulier en utilisant la réplication afin de détecter les erreurs silencieuses [5].
Les problèmes sont donc nombreux, suivant les caractéristiques des applications considérées, des plates-formes sur lesquelles s'exécutent les applications, et des techniques utilisées pour limiter la perte de travail lors d'une panne.
Un aperçu complet des travaux de l'équipe ROMA (Optimisation de ressources: modèles, algorithmes, et ordonnancement) est disponible sur http://www.ens-lyon.fr/LIP/ROMA/.
Note:
[1] G. Aupy and Y. Robert. Scheduling for fault-tolerance: an introduction. In NSF/IEEE-TCPP Curriculum Initiative: Topics in Parallel and Distributed Computing. Springer, 2018.
[2] A. Benoit, A. Cavelan, V. Le Fèvre, Y. Robert, and H. Sun. Towards optimal multi-level checkpointing. IEEE Transactions on Computers, 66(7):1212–1226, 2017.
[3] A. Benoit, A. Cavelan, Y. Robert, and H. Sun. Optimal resilience patterns to cope with fail-stop and silent errors. In Proceedings of IPDPS, the Int. Parallel and Distributed Processing Symposium. IEEE, 2016.
[4] L. Bautista-Gomez, A. Benoit, A. Cavelan, S. K. Raina, Y. Robert, and H. Sun. Which verification for soft error detection ? In Proceedings of HiPC, the Int. Conference on High Performance Computing. IEEE, 2015.
[5] A. Benoit, A. Cavelan, F. Cappello, P. Raghavan, Y. Robert, and H. Sun. Coping with silent and fail-stop errors at scale by combining replication and checkpointing. J. Parallel and Distributed Computing, 2018.
Populaires